6 The Write-In Databases
The write-in databases are subjective, because they contain only publicly, and legally available information collected and organized by the Listen Local Collaboration with the oversight of local music curators. The write-in database of Listen Local Slovakia contains music that our Slovak music curators think to be Slovak music in one way or another.
The Write-in Databases are supported by the Digital Music Observatory with automated data collection from various open data sources and APIs. They follow the idea of the semantic web and linked data. Linked Data services allow a seamless cooperation among networked computer services.
Our write-in databases work with following data providers (see later 6.2Automated Write-in), but they always remain under human (curatorial) control.
Biographical data: we collect data about the musicians and their bands/ensembles age, place of birth/formation, and connect it to their music (recordings, albums, compilations and eventually to events.) - Wikidata, the database behind the English and national language Wikipedias.It connects many high-quality global databases. - MusicBrainz is a community-maintained open source encyclopedia of music information. It used by many applications, for example, the Wikipedia language versions, to provide more precise open source information about musicians and their music (Whenever an artist has a MusicBrainz entry, Wikipedia uses it via Wikidata. AccousticBrainz also relies on MusicBrainz.) It is compatible with most music services and it is more than likely that they rely on them. ► See further data about artists and their ►
Data about the music: We collect information about the recordings (including the collection of recordings in the form of albums and compilations) of the artists that we follow. We use the following sources to desribe their data: - Essentia is an open-source library and tools for audio and music analysis, description and synthesis. It uses machine learning and deep learning to guess if the singer’s voice is male or female, the key of the song, the mood, the brightness, and other qualities. It allows us to automatically create playlists (for further curatorial oversight) like “Dark female voices of Slovakia”, “Energetic Punk from Lithuania”, or “Happy Singer-Songwriters from Budapest” (it’s a very short list). Essentia is free to use for non-commercial applications, and needs a commercial licensse for other applications. - AccousticBrainz is a free research database that contains many Essentia models of all songs which have a MusicBrainz entry. Our initial aim is to connect our database to MusicBrainz, and retrieve Essentia features from AccousticBrainz, because they are very well documented, and they are certainly covered by the non-commercial license. - Spotify API, a rich and open API of the Spotify music platform. It provides us with use information (followers, popularity) and high quality musicology information from the EchoNest AI application (like dancability, accousticness, etc.) - YouTube API—planned. - Deezer API—planned.
Under the hood, these services connect us to various data authorities and standards to make sure that our data is high quality.
Quality control and disambigouation: We try to improve the quality of our automatically collected data, and reduce the burden of our curators with using various data standards. - schema.org, a collaborative, community activity with a mission to create, maintain, and promote schemas for structured data on the Internet, on web pages, in email messages, and beyond. This makes sure that various Google, Microsoft, and open source services understand our data correctly. - ISNI - International Standard Name Identifier, the international ISO standard for name disambigouation, see for example JANKAUSKAITE, INGA - VIAF - Virtual International Authority File, a name disambigouation service developed by many libraries, see for example Jankauskaitė, Inga 1981– - ORCiD - Open Researcher and Contributor ID, for a proper attribution in publications and other IP for our curators and contributors, see for example Daniel Antal - ISRC - The International Standard Recording Code, which is a standardized code of each commercially released recording. The code contains the release datum and uniquely identifies any recording that is commercially released and therefore legally can be played in radios, streaming platforms (See a note9 on non-commercial releases, for example, on Bandcamp. The ISRC code connects a producer or a performer to a recording. - ISWC - The International Standard Musical Work Code is a unique, permanent and internationally recognized reference number for the identification of musical works—i.e, it is connected to the composer of the music or lyrics. It is the international standard ISO 15707:2001. For the sake of clarity, a musical work is composed of a combination of sounds, with or without accompanying text. Text only (lyrics) works cannot receive an ISWC.
6.1 Getting Started with a New Listen Local Database
The easiest way to start a national/regional/city database is this:
Quick start with the write-in database: we provide you a few hundred links to Spotify profiles in an easy to click table and Google Spreadsheet who we think fit into your curatorial profile, for example, artists who we think are Czech or Lithuanians or Ukrainians or Flemish. This gives a jump start with about 4000-5000 songs that can already offer some very cool microservices and showcase the power of trustworthy, human controlled AI.
Verifying information from WikiData is a bit more complex verification of data we found on Wikidata. This is a bit more complex verification task, but this offers us the connectivty to a host of information sources.
Manual Write-in: Getting Started with Manual Entries into the Listen Local Dataset is more time consuming and this will add usually less known and upcoming artists.
Write-in from Bandcamp. This will be shown later.
6.1.1 Quick start with the write-in database
To quickly populate a starting write-in table, we get initial data from Spotify. We create country/region specific tables for this purpose. In this case, we show the Czech verification table. Czech, Slovak and Czechoslovak identities are fluid, so we may accidentally find there Slovak or not clearly Czech or Slovak artists.
You can completely leave out artists that accidentally made it to the table, just check verified_curator to 1 and leave all others 0 to know that you have already formed an opinion, and it is to leave the artist out. No further work will be done if the row has verified_curator 0. However, all marked 1 will be added to our database and we will start searching and recording data about the artist immediately.
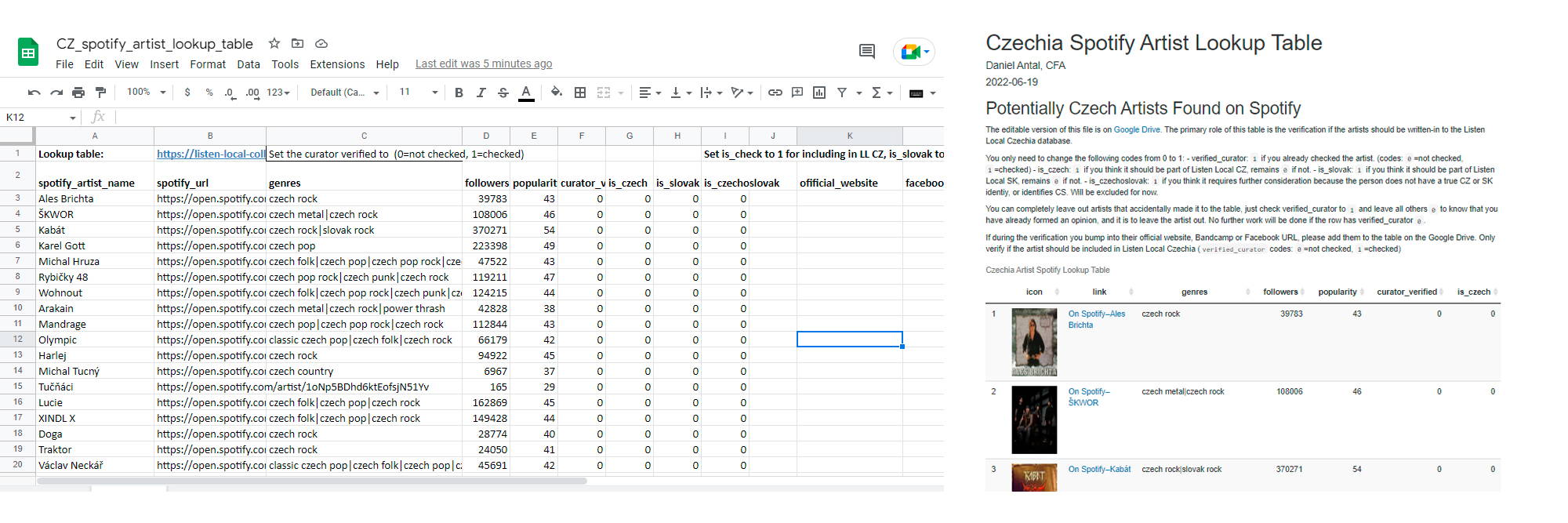
Figure 6.1: A quick verification of the identities we found on Spotify.
Via the Spotify Web API, we will get some information about this aritsts, and often we will be able to connect them to their Wikidata, MusicBrainz, AudioBrainz or other database entries. But starting with Spotify is not ideal, because it has little biographical data.
Currently available tables: LT; CZ, UA, Flemish—click throught to see the easily clickable html version and the connecting Google Drive file with it.
6.1.2 Verifying information from WikiData
Wikidata is the database that powers the English and national language Wikipedias. It is a very high quality data source, because it is connected to library identify verification services. While Wikipedia’s text is not always very good quality, the database is.
As opposed to the Spotify lookup table, here we have less artists but with a lot more information. The aim of the following table is to help a human verification of the identity of Lithuanian singers or Czech singers or Flemish singers.
The aim of this table is to get a first experience in human verification, and you do not necessarily have to fill out all information.
- Please check that the Wikipedia, Spotify and Musicbrainz links link to the same person.
- Please check if the offical website of the artist can be found (no Facebook pages.)
- If the official website is missing, fill it in as https://example_singer.com/.
- If the date of birth is missing, try to look it up in a reliable source.
- If the place of birth is odd, just try to look up the real place of birth in a reliable source.
- You can add an artits who is not in the table. Do not add bands at this point, only solo artists. Make sure that the artist has a properly spelled name, and at least one of the possible URLs,i.e. at least Wikipedia, Spotify, Musicbrainz, or official website. For artists only on Bandcamp, etc… we will get there next time.
To help an easy workflow, we created two versions of this table: an easy-to-click through HTML version, and an (almost) identitcal, but easier to edit Google Spreadsheet version. This table contains all female and male singers known to Wikipedia.
Beware that the table is not clickable in PDF and Word outputs. The editable version for this table can be found on the Google Drive (you can click here if you have access to the Lithuanian files.)
You must edit at least one column:
curator_verified: It is set by default to 0. Change it to 1 if you did not need to modify anything. Change it to 2 if you did make a change.
And in case you make any changes:
curator_comment: Explain in the comment field with a few words what did you change.
Do not change the ordering of the table and the current columns. You can add further columns for yourself, but do not change the table structure.
For example, the last entry is 55 Jarosekas Quartet, which should be changed to
curator comment: Not a singer, but an quartet. [this means that we should move this information to the page of bands and ensembles.] All other information can be left as it is.
curator_verified: from 0 [not yet checked] 2 [means that the curator checked the row 55 and corrected it.]
- LT_singers: the first version of the Lithuanian singer identification table, also used as an example here. The editable version for this table can be found on the Google Drive (you can click here if you have access to the Lithuanian file.
- HU_singers: the first version of the Hungarian singer identification table.
- CZ_singers: the first version of the Czech singer identification table. The editable version for this table can be found on the Google Drive (you can click here if you have access to the Czech files.)
- UA_singers: the first version of the Ukrainian singer identification table. The editable version for this table can be found on the Google Drive (you can click here if you have access to the Ukrainian files.)
- BE_singers: the first version of the Belgian singer identification table with a special column for separating Vlaams and other singers. The editable version for this table can be found on the Google Drive (you can click Belgium singer table here if you have access to the Belgian files.)
6.1.3 Manual Write-in: Getting Started with Manual Entries into the Listen Local Dataset
- Start with the craation of Spotify playlists. Add artists that are relevant to your playlist. Please check out a starting playlist Listen Local Utrecht.
Figure 6.2: Start a locally relevant playlist on Spotify
Create a long-list of artists who you think are Flemish / Lithuanian.
Create shorter lists per city (artists who you think are certainly connected to Antwerpen, Gent, Vilnius, Kaunas.)
If unsure, short of time, leave the artist for the time being on the long list of Flemish, Lithuanian. If we already know that the artist can be meaningfully connected to Lithuania or Flanders it is a good start. Start with the easy and refine.
- Each playlist should be organized according to a location
We will have to refine many times how we connect artists to a scene. For example, works in Gent, connected to the Gent scene. In NL, Danny Vera lives in Middleburg, Zeeland, but he records Americana in Nashville, Tennessee. In most contexts, he is Dutch – he dethroned The Queen as the most played radio artist in NL recently, he is very Dutch. In a few cases it may be relevant to connect him to Middleburg, but not often – there is not much of a Middleburg scene. And it is very useful to connect him to Nashville.
More on ► location not yet written
- Let Reprex’s Listen Local System create the initial write-in database.
The Listen Local developer team will machine create a long list of Flemish, Lithuanian, and Ukrainian music from Wikipedia, MusicBrainz, Spotify, Bandcamp. We will collect much information about the music contents, the recording licensing information, biographical information together. We will add candidates from our own, machine-based collection.
- Review the datasets in Google Spreadsheet.
Each curator will have a single dataset. The Flanders dataset will include optionally city, scene, language and gender. The Gent dataset will be a subset of the Flanders more general dataset. (You can put more detail into Gent only.)
- Publish the first version of the dataset
We will publish the first version of Listen Local Lithuania dataset with authorship of the the Lithuania curator, the Listen Local Flanders dataset with the authorship of the Flanders curator. ► Your Intellectual Property.
- Ask the crowd to nominate more artists
See (crowdsourcewritein) Crowdsourcing information.
- Ask artists to opt-in and take ownwership of their data
See (optin) Opt-in and opt-out.
6.2 Automated data connections
First, we will create a workflow to ingest all relevant data for us from MusicBrainz, which will also allow us to ingest all data from AcousticBrainz. MusicBrainz regularly creates a PostgreSQL dump of all its database—however, we only need a few selet country-related artists. Boti creates a scipt that retrieves the dump regularly, and selects artist biographies and connected recordings, then places them in a small SQLite database. That will be included in our Listen Local Databases and matched against AcousticBrainz (Essentia), Spotify (EchoNest), and Wikidata entries.
We will later create a reverse workflow to make sure that our artists are included on MusicBrainz, which makes sure that many other web services have the correct data about them.
6.2.1 Essentia & AccousticBrainz
Essentia is an open-source library and tools for audio and music analysis, description and synthesis. It uses machine learning and deep learning to guess if the singer’s voice is male or female, the key of the song, the mood, the brightness, and other qualities. It allows us to automatically create playlists (for further curatorial oversight) like “Dark female voices of Slovakia”, “Energetic Punk from Lithuania”, or “Happy Singer-Songwriters from Budapest” (it’s a very short list).
Essentia is free to use for non-commercial applications, and needs a commercial licensse for other applications.
AccousticBrainz is a free research database that contains many Essentia models of all songs which have a MusicBrainz entry. Our initial aim is to connect our database to MusicBrainz, and retrieve Essentia features from AccousticBrainz, because they are very well documented, and they are certainly covered by the non-commercial license. Because AcousticBrainz is no longer continued from 1 July 2022, we will get into touch with them how we can replace this source for the future.
For artists not on MusicBrainz, our engineer, Boti will create a workflow to run their songs through Essentia. However, we will do this when we have already a public database, because we will get in touch with Essentia and AccousticBrainz to clear a non-commercial license and to make sure that our artists get to MusicBrainz & AccousticBrainz [it really helps their discovery.]
The creator of AccousticBrainz also got a MusicAIRE grant and we can cooperate with them easily.
6.2.2 MusicBrainz
MusicBrainz is a community-maintained open source encyclopedia of music information. It used by many applications, for example, the Wikipedia language versions, to provide more precise open source information about musicians and their music (Whenever an artist has a MusicBrainz entry, Wikipedia uses it via Wikidata. AccousticBrainz also relies on MusicBrainz.) It is compatible with most music services and it is more than likely that they rely on them.
We already got in touch with MusicBrainz about a collaboration. It is a real disadvantage for an artist or record release not to be on MusicBrainz, but MusicBrainz is a complicated SQL database.
6.2.3 Wikidata
Wikidata is a big semantic web (SPARQL) database that connects many web services to Wikipedia, for example, the IFNI and VIAF namespaces, that correctly identify artists and bands if they use the same name.
Through Wikidata, we often can get the correct biographical information of artists, and connect to their social media, streaming platforms, and other web services. Obviously, artists are really at disadvantage who do not have a Wikidata entry, because Wikidata is a very useful connecting point of various global services. Currently the LLcollectoR R library maintained by Daniel connects to this source and reads in the data.
Wikidata services mainly Wikipedia pages, so we can place new artists there if we create a Wikipedia entry for them, preferably in English and in their own language. We can machine-generate a well-formatted Wikipedia page from our database, where the curator only needs to adjust 2-3 paragraphs of text. This will help the artist a lot, but this requires work. We will do this with 10-20 artists to measure the effect, but later we will offer this as one of our microservices.
6.3 What will we do with this data?
- The Listen Local System uses the semantic web to find reliable information about the biographies and works of these artists. Once we clarified the identity of the artist, we will automatically connect plenty of information, and curators will receive similar tables to review critical information.
- We created this information from Wikipedia’s database, Wikidata, which contains all the data of all well formatted Wikipedia pages. Some Wikipedia pages are not well formatted, we will get back to those later. We will create similar discovery tables from Bandcamp, Spotify, MusicBrainz. This is a fast way of creating the
Lithuanian Demo Music Database, and pre-populate it with a large amount of data to start developing new apps and services. - We will always flag missing information and wrong information, and we will show with data comparisons why it is damaging to the artist (in this case, Lithuanian singers) to have wrong information, for example, erroneous or not professionally edited Wikipedia pages.
- We will ask artists to opt-in and self-correct that information and offer them services to correct their biographical information on websites that Spotify, YouTube, journalist, etc. use to learn about their music.
This is just the beginning.
Our application will help our curators to develop new playlist, for example, just from this information, the Listen Local App will give you a first version of Czech singer-songwriters playlist, a Czech Acoustic Singer-Songwriter Women list on Spotify (and later on YouTube.) The curator can add /change songs on that list and find new artists unknown to us. First microservice prototypes for music fans and supporters of our ideas((https://listen-local-collaboration.dataobservatory.eu/listenlocal.html#prototype-fans-supporters)
We can offer a service to band managers/lables to make verify that all their artists information is properly presented in all major web services, be it information services like
All Music,MusicBrainz,FreeDBorWikipedia(all langauge versions) or streaming platforms such asSpotifyorYouTUbe. First microservice prototypes for artists and managers
We will create a regularly updated, automatically created list of all Czech singers in this table, with their single most popular song on Spotify. When the popularity of their songs change, the playlist will be updated (every week once.)
- We will measure the relative performance of artists with correct and incorrect data, and before/after scenarios. We will create write-in databases for countries where we have no curators now (for example, Latvia), to measure week by week the performance difference. For example, how do 10 Czech aritsts of Spotify poularity of 5 compare to 10 Latvian artits of popularity 5 one week, one month, two months after the Czech data was corrected but the Latvian not? etc.
6.3.1 How location matters?
We will be discussing this part in mid June. Feel free to become a co-author of this document and get credited. See issue 2
And we will start discussing an important aspect of the project – how we connect artists to a geographical location? We need to define a few types of relationships: Katarzia was born in Nitra, SK.Katariza lives in Prague, CZ.Katarzia belongs to the singer-songwriter scene of ____ (Slovakia?)Danny Vera was born in Middleburg, NL.Danny Vera belongs to the scene of Memphis, Tennessee, US.
By connecting to locations artists, we will be able to provide locally relevant services, and locally relevant recommendations (a few of our simple microservice ideas can be found here.) One way of going forward is to continue a series of short interviews with artists friends. In our interviews, we can ask anything and publish the interview on Data & Lyrics, and later on the LL website. The must have features of the interview:
- Where is the artist based. How is she relating to this place?
- Where would the artist be heard? Any professional, emotional, etc. reason to target the city,region, country of …
- What would the artist recommend to visit, see, hear, check out in the city where she lives
- What is the knowledge level and opinion of the artist of AI in music?
This way we naturally bring in issues of connection to localities, music travelling to new places, making recommendations and we can define how we want to connect artists to locations. For example, if our aim is to connect visitors of Utrecth to local small venue programs in Utrecht then we must have a relationship with Moon Moon Moon often plays in Utrecht. Or, if we want to say that Katarzia belongs to the scene of Bratislava, we must say that she is connected to the Bratislava acousting sound even though she lives in Prague. Our current starting point – that we get from reliable data sources – are artist birth places, which is often a good starting point, and anyways, we can already create playlist of artists who were born in Vilnius or Budapest.
Get inspired:
From Slovakia to Prague: Katarzia
Duka’s Mission: Collaborate With Musicians From Every Country On Earth
Twentees: The Mountains Are Higher Next Door And They Understand Our Lyrics
You can contribute with further interviews. Ask the artist in a similar fashion.
Where is (are) the artis(s) coming from—literally and physically?
Where are they going to? Where they want to find new audiences? Where they want to be heard?
Ask about their personal opinion or knowledge related to AI, algorithm, and recommendations of YouTube and Spotify. (Does not matter what they have to say.)
Ask them to recommend some of their own music.
Ask them to recommend places for a fan who would be visiting their town (music venues, places of interest, or whatever may connect a fan to their place.)
Ask a few photos for the post (with photo credits.)
Further blogposts: Listen Local: Why We Need Alternative Recommendation Systems
We welcome any blogposts related to your work, particularly if they have to do something with music, data, lyrics, locations, scenes, genres, feminism, and making the music ecosystem more just and sustainable.
Non-commercial releases can be seen as demo or bootleg (illegal) recordings. The problem with demo recordings if they are public that the artist cannot be paid for their use—the role of the ISRC code is to record who should be paid for producer’s and performer’s neighboring rights royalties.↩︎